最好不要在夕阳西下的时候去幻想什么,而要在旭日初升的时候即投入工作。——谢觉哉
还在为壁纸发愁吗?今天手把手教你写爬虫!
注意!仅供学习交流使用,请勿用在歪门邪道的地方!技术只是工具!关键在于用途!
顺带一提,大家一定要注意不要违法了哦
1
2
3
4
5
| 第二百八十五条 违反国家规定,侵入国家事务、国防建设、尖端科学技术领域的计算机信息系统的,处三年以下有期徒刑或者拘役。
二百八十六条 违反国家规定,对计算机信息系统功能进行删除、修改、增加、干扰,造成计算机信息系统不能正常运行,后果严重的,处五年以下有期徒刑或者拘役;后果特别严重的,处五年以上有期徒刑。
违反国家规定,对计算机信息系统中存储、处理或者传输的数据和应用程序进行删除、修改、增加的操作,后果严重的,依照前款的规定处罚。
故意制作、传播计算机病毒等破坏性程序,影响计算机系统正常运行,后果严重的,依照第一款的规定处罚。
第二百八十七条 利用计算机实施金融诈骗、盗窃、贪污、挪用公款、窃取国家秘密或者其他犯罪的,依照本法有关规定定罪处罚。
|
如果爬虫程序采集到公民的姓名、身份证件号码、通信通讯联系方式、住址、账号密码、财产状况、行踪轨迹等个人信息,并将之用于非法途径的,则肯定构成非法获取公民个人信息的违法行为。
除此之外,根据相关规定,对于违反国家有关规定,向他人出售或者提供公民个人信息,情节严重的,窃取或者以其他方法非法获取公民个人信息的,均可构成成“侵犯公民个人信息罪”,处三年以下有期徒刑或者拘役,并处或者单处罚金;情节特别严重的,处三年以上七年以下有期徒刑,并处罚金。
重点关注:下列情况下,爬虫有可能违法,严重的甚至构成犯罪。
- 1.爬虫程序规避网站经营者设置的反爬虫措施或者破解服务器防抓取措施,非法获取相关信息,情节严重的,有可能构成“非法获取计算机信息系统数据罪”。
- 2.爬虫程序干扰被访问的网站或系统正常运营,后果严重的,触犯刑法,构成“破坏计算机信息系统罪”
- 3.爬虫采集的信息属于公民个人信息的,有可能构成非法获取公民个人信息的违法行为,情节严重的,有可能构成“侵犯公民个人信息罪”。
正题开始,首先创建一个maven项目
引入依赖
1
2
3
4
5
6
7
8
9
10
11
12
| <dependencies>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.10.2</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.51</version>
</dependency>
</dependencies>
|
完整pom.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| <?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>BeCarefulInPrison</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.10.2</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.51</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
</project>
|
创建主类
1
2
3
4
5
6
7
8
9
10
|
public class BeCarefulInPrison {
public static void main(String[] args) {
}
}
|
那么我们开始寻找要爬取的页面
这里使用http://yywallpaper.top/classify/3
这个壁纸网站作为教学
我们进入这个页面后打开控制台,刷新页面后可以看到一个请求
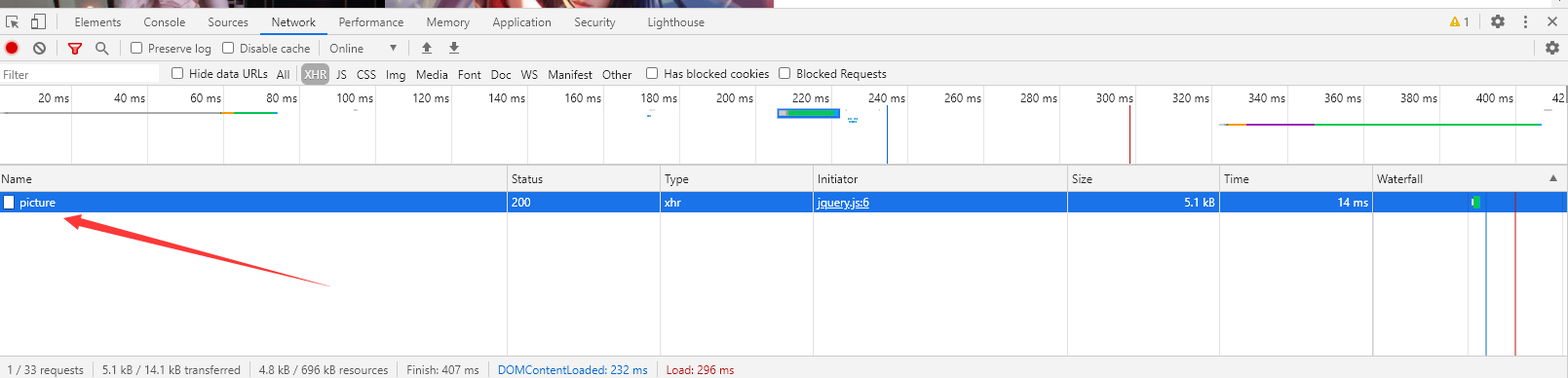
点开Headers
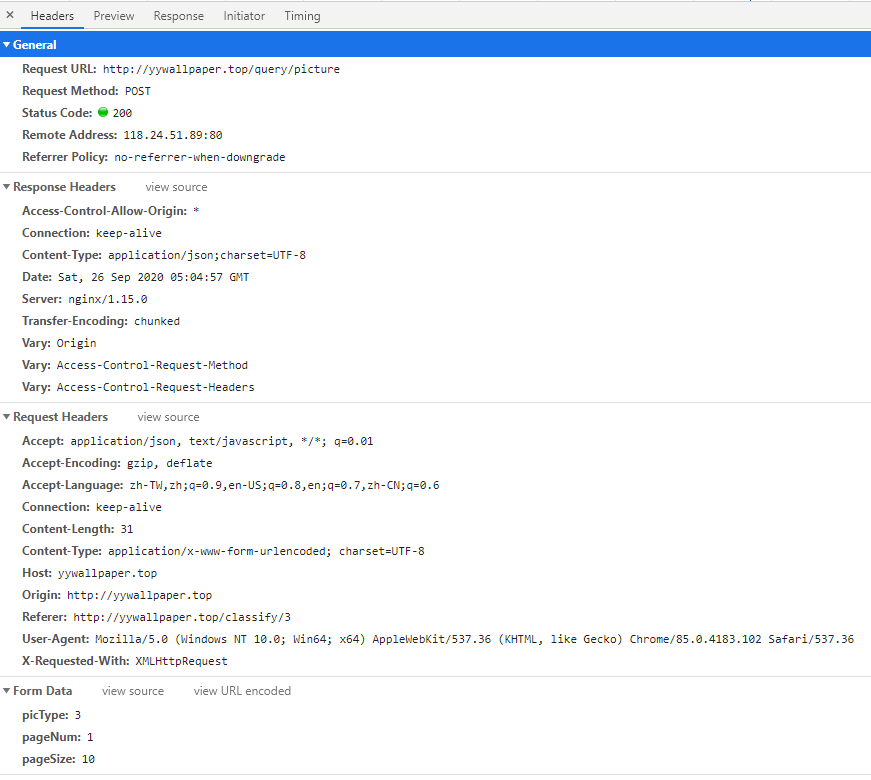
发现是POST方式,参数有三个,一个是picType分类,一个是PageNum当前页码,pageSize每页条数
那么我们来模拟一下请求
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import java.io.IOException;
import java.util.List;
public class BeCarefulInPrison {
public static String WEB_URL = "http://yywallpaper.top/query/picture";
public static List<String> goToJail(String type, String pageNum, String pageSize) throws IOException {
Connection connection = Jsoup
.connect(WEB_URL)
.ignoreContentType(true)
.timeout(60000);
connection.data("picType", type);
connection.data("pageNum", pageNum);
connection.data("pageSize", pageSize);
Document document = connection.post();
System.out.println(document.html());
return null;
}
public static void main(String[] args) throws IOException {
goToJail("3", "1", "10");
}
}
|
输出结果
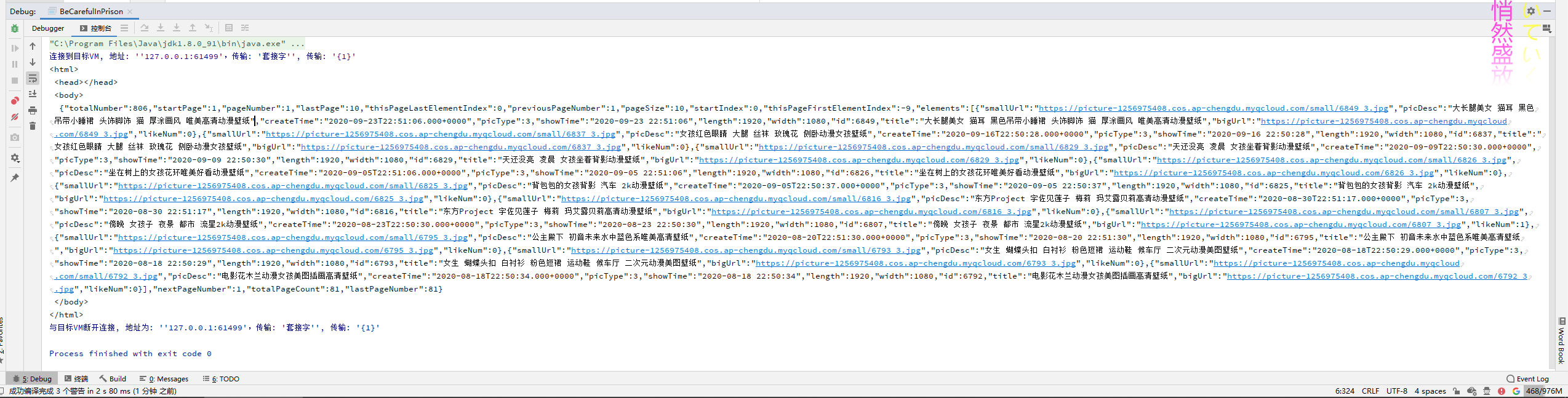
可以看到是一个内容为JSON格式文本的html页面
然后我们把中间的JSON字符串取出来
1
| String jsonString = document.getElementsByTag("body").text();
|
使用我们的JSON工具进行解析
1
2
3
4
5
6
7
8
9
10
11
12
|
JSONArray elements = JSON.parseObject(jsonString).getJSONArray("elements");
List<String> images = new ArrayList<>(10);
for (int i = 0; i < Integer.parseInt(pageSize); i++) {
JSONObject jsonObject = JSON.parseObject(elements.get(i).toString());
String image = jsonObject.getString("bigUrl");
images.add(image);
}
return images;
|
完整代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
| import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class BeCarefulInPrison {
public static String WEB_URL = "http://yywallpaper.top/query/picture";
public static List<String> goToJail(String type, String pageNum, String pageSize) throws IOException {
Connection connection = Jsoup
.connect(WEB_URL)
.ignoreContentType(true)
.timeout(60000);
connection.data("picType", type);
connection.data("pageNum", pageNum);
connection.data("pageSize", pageSize);
Document document = connection.post();
String jsonString = document.getElementsByTag("body").text();
JSONArray elements = JSON.parseObject(jsonString).getJSONArray("elements");
List<String> images = new ArrayList<>(10);
for (int i = 0; i < Integer.parseInt(pageSize); i++) {
JSONObject jsonObject = JSON.parseObject(elements.get(i).toString());
String image = jsonObject.getString("bigUrl");
images.add(image);
}
return images;
}
public static void main(String[] args) throws IOException {
List<String> images = goToJail("3", "1", "10");
images.forEach(System.out::println);
}
}
|
输出结果
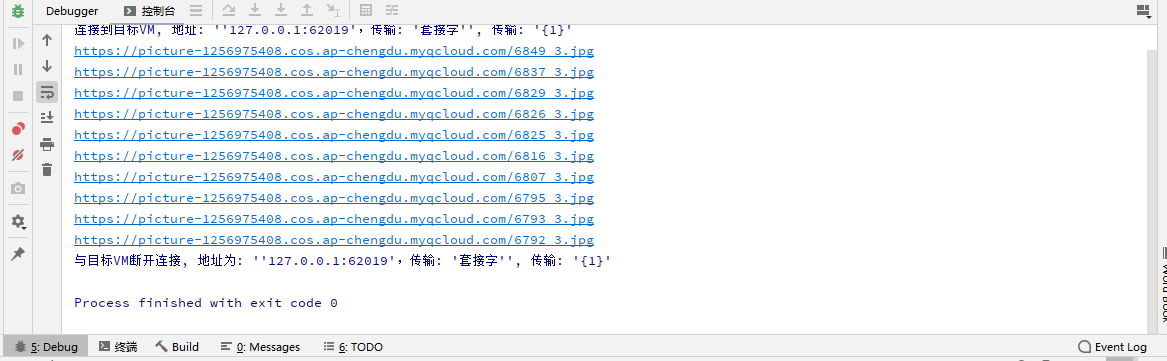
然后我们可以下载到本地
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| public static void downloadPicture(String imageUrl, String path) {
URL url = null;
try {
url = new URL(imageUrl);
DataInputStream dataInputStream = new DataInputStream(url.openStream());
FileOutputStream fileOutputStream = new FileOutputStream(new File(path));
ByteArrayOutputStream output = new ByteArrayOutputStream();
byte[] buffer = new byte[1024];
int length;
while ((length = dataInputStream.read(buffer)) > 0) {
output.write(buffer, 0, length);
}
fileOutputStream.write(output.toByteArray());
dataInputStream.close();
fileOutputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
|
在此之前我们还要对文件名截取一下
1
2
3
4
5
6
7
8
9
10
| public static void main(String[] args) throws IOException {
List<String> images = goToJail("3", "1", "10");
images.forEach(image -> {
// 获取文件名
String fileName = image.substring(image.lastIndexOf("/") + 1);
System.out.println(fileName);
//下载到本地
downloadPicture(image, "C:\\Users\\Doyle\\Desktop\\file\\image\\" + fileName);
});
}
|
运行后输出文件名
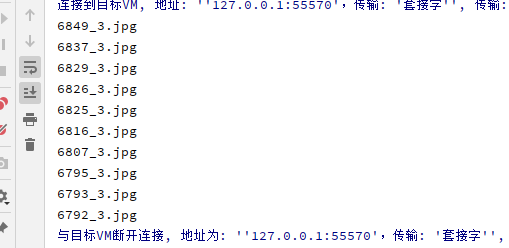
然后打开目录
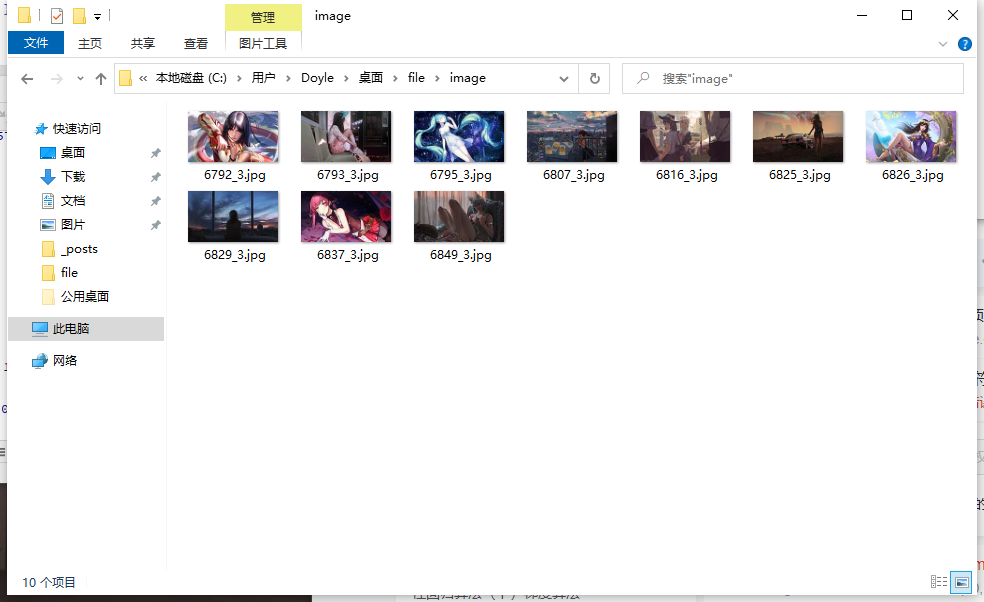
图片已经下载完成啦
