
explain
人们很少做他们相信是对的事,他们做比较方便的事,然后后悔。——鲍勃.迪伦
使用explain+SQL
作用:
表的读取顺序
数据读取操作的操作类型
哪些索引可以使用
哪些索引被实际使用
表之间的引用
每张表有多少行被优化器查询
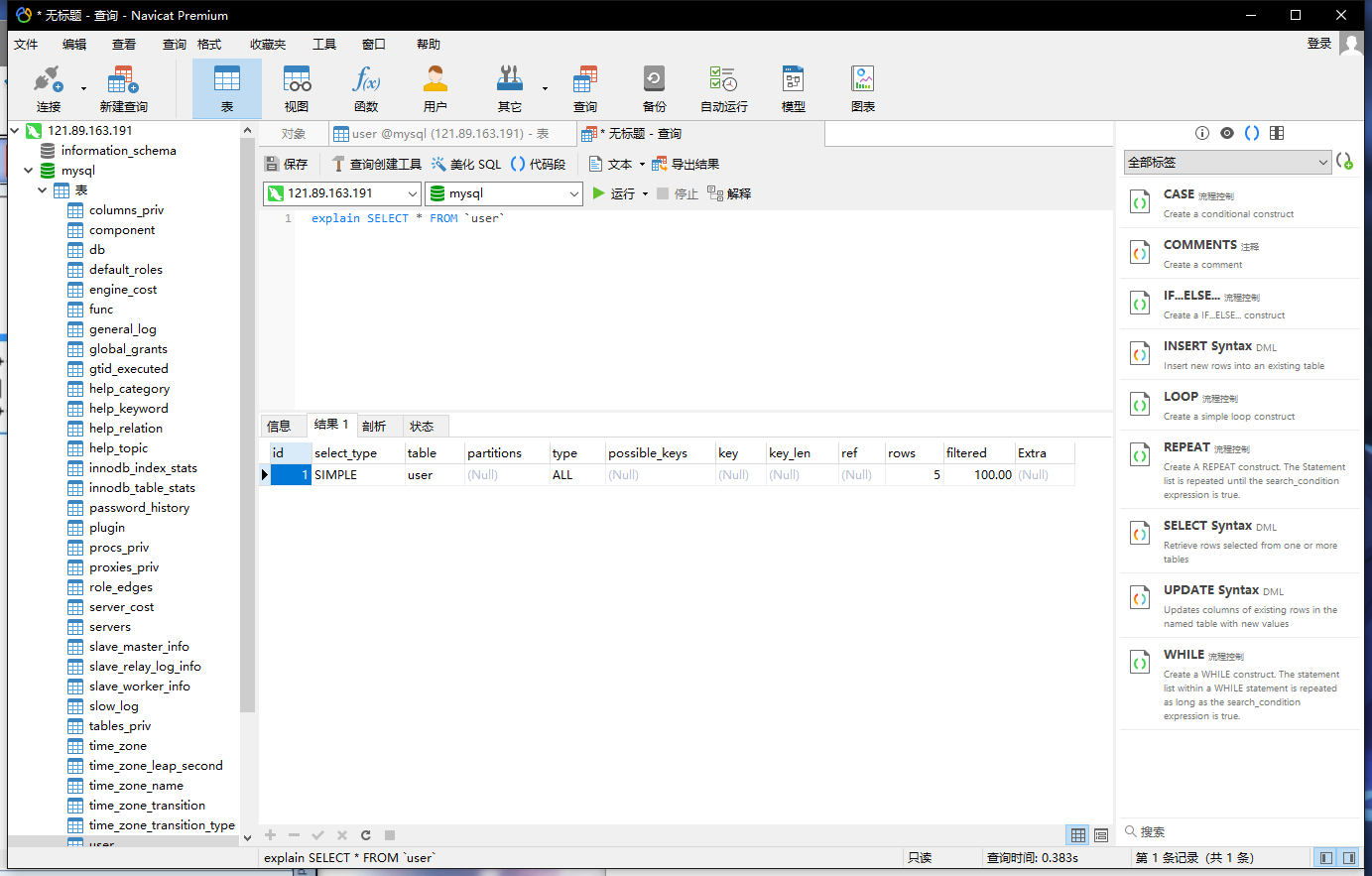
id select_type table partitions type possible_keys key key_len ref rows filtered Extra
id:查询的序列号,包含一组数字,表示查询中执行select字句或操作表的顺序
id值越大执行优先级越高,id相同情况下执行顺序从上到下
select_type:查询的类型,主要是用于区别普通查询、联合查询、子查询等的复杂查询
simple简单的select查询,不包含子查询、UNION
primary子查询的最外层
subquery子查询的内层
derived表示 FROM临时表,这个表被标记为衍生
union在union后面的查询,若union包含在from字句的子查询中,外层select被标记为derived
union result从union表获取结果的select
type:访问类型排列
从最好到最差
常用
system>const>eq_ref>ref>range>index>ALL
system系统表
const通过索引一次就找到了,例如主键查询
1 | explain select * from user where id = "" |
eq_ref连表唯一条件
1 | selec * from user,user_info where user.id = user_info.id |
ref返回匹配某个单独值的所有行
1 | explain SELECT * FROM `user` WHERE HOST = "%" |
range范围查询
1 | select * from user where id between 0 and 10 |
index全索引扫描
1 | select id from user |
all全表扫描
全部
system>const>eq_ref>ref>fulltext>ref_or_null>index_merge>unique_subquery>range>index>ALL
possible_keys:显示这张表可能用到的全部索引
key:实际用到的索引
key_length:索引使用的最大可能长度,为字节数,越短越好
ref:显示索引使用的列,const表示匹配常量
rows:估算查询需要读取的行数
Extra:额外信息
Using filesort:mysql无法利用索引完成的排序叫文件排序
Using temporary:使用了临时表
Using index:用到了覆盖索引(Covering Index:查询的列被索引覆盖),同时出现using where,说明索引被用于查找,反之则用于读取数据
Using where:说明用到了where
Using join buffer:使用了连接缓存,多次join时出现
impossible where:where条件错误,例如id = xxx and id = xxx
select tables optimized away:没有group by时,优化MIN/MAX或者COUNT(*)
distinct:找到第一个匹配的元素后停止查找相同的值