
INSERT ... ON DUPLICATE KEY UPDATE Statement
打开
mysql文档,总会有新发现。——碧安瑶
我们在使用INSERT语句时,有时会有这样的需求,不存在就新增,存在就更新
此时我们可以使用INSERT ... ON DUPLICATE KEY UPDATE语句
就像mysql官方文档中提到的那样,我们如果将a列设为UNIQUE唯一索引或者主键时,并且当前表已经存在了a=1的数据,对于这种情况,下面两条sql的结果是相等的
当然如果不满足上方条件,则会新增一条数据
1 | INSERT INTO t1 (a,b,c) VALUES (1,2,3) |
对于InnoDB引擎的表,此处的新增可能会触发自增列,但修改操作不会触发
如果上方的唯一索引再加一个b列,则上方第一条sql和下方sql结果相等
1 | UPDATE t1 SET c=c+1 WHERE a=1 OR b=2 LIMIT 1; |
注意如果此处a=1 or b=2匹配多行,则只会更新一行,所以我们需要避免在有多个唯一索引的表上使用本语法
我们在表内没有满足条件的数据时执行该sql,返回影响行数为1
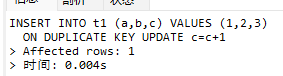
我们再次执行
可以看到影响行数为2
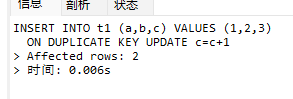
这说明新增操作返回1,修改操作返回2
但如果我们修改的值没有变化,则为0,例如:
1 | INSERT INTO t1 (a,b,c) VALUES (1,2,3) |

如果使用 mysql_real_connect()来连接mysql,修改的值没有变化时,还是返回1
并且如果我们触发了自增,也可以使用 LAST_INSERT_ID()函数获取自增后的值
我们还可以在ON DUPLICATE KEY UPDATE后方使用VALUES函数来获取上方INSERT语句中某列的值例如
1 | INSERT INTO t1 (a,b,c) VALUES (1,2,3),(4,5,6) |
上面的sql和下面这条sql执行结果也是相同的
1 | INSERT INTO t1 (a,b,c) VALUES (1,2,3) |
从 MySQL 8.0.20开始,不推荐使用 VALUES ()来引用新的行和列,并且在将来的 MySQL 版本中可能会删除。相反,应该使用行和列别名
Mysql8.0.19之后,我们可以给表和列取别名,例如:
1 | INSERT INTO t1 (a,b,c) VALUES (1,2,3),(4,5,6) AS table1 |
以及
1 | INSERT INTO t1 (a,b,c) VALUES (1,2,3),(4,5,6) AS table1(m,n,p) |
就先写这么多吧