害怕树敌的人永远得不到真正的朋友——哈兹里特
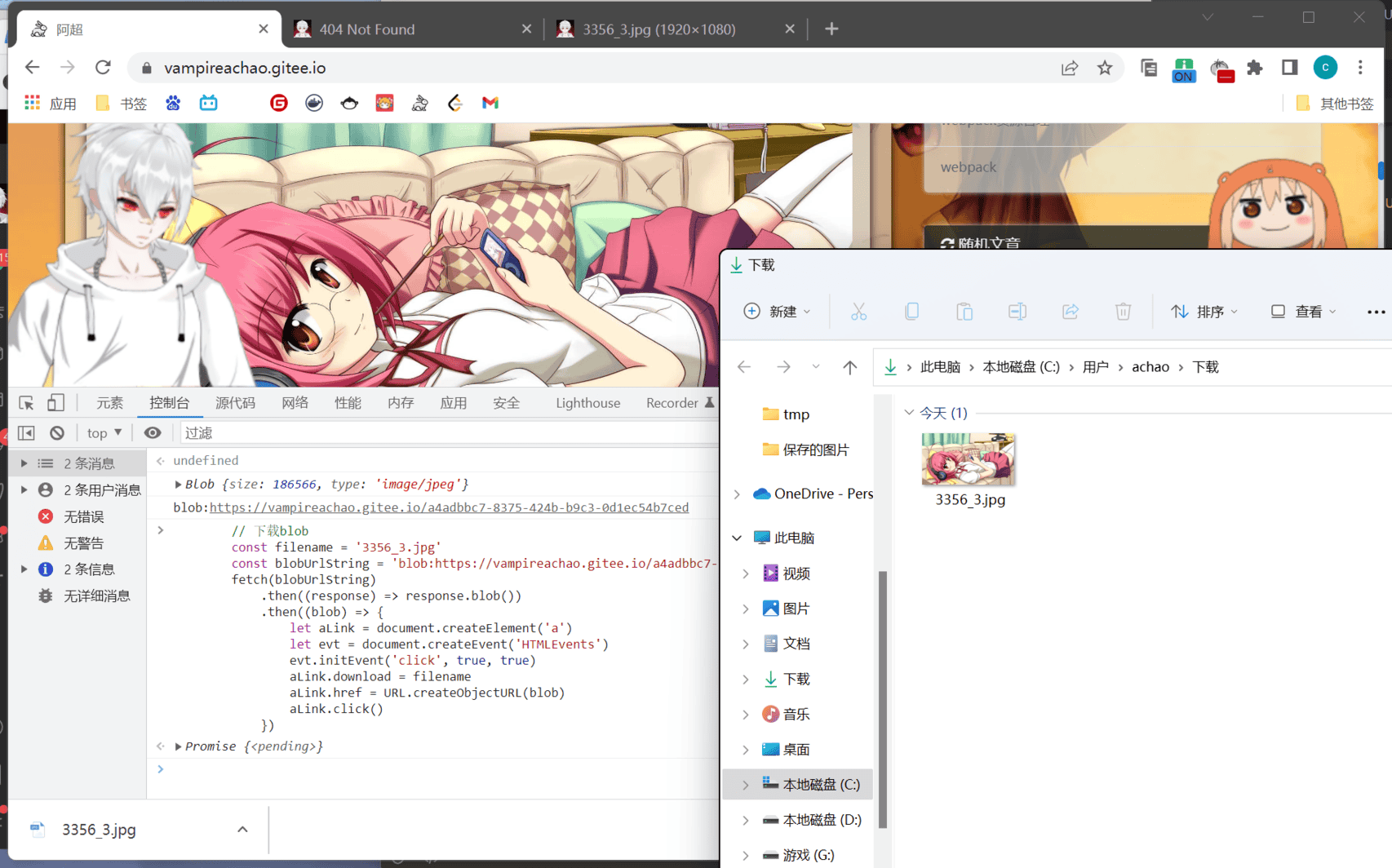
首先是普通资源URL转换为blobUrl
1
2
3
4
5
6
7
8
9
10
11
12
13
|
const xhr = new XMLHttpRequest();
xhr.open('GET', 'https://VampireAchao.github.io/imgs/preview/3356_3.jpg', true);
xhr.responseType = 'blob';
xhr.onload = function (e) {
if (this.status == 200) {
var blob = this.response;
console.log(blob);
console.log(URL.createObjectURL(blob))
}
};
xhr.send();
|
这边执行后,打印出了结果
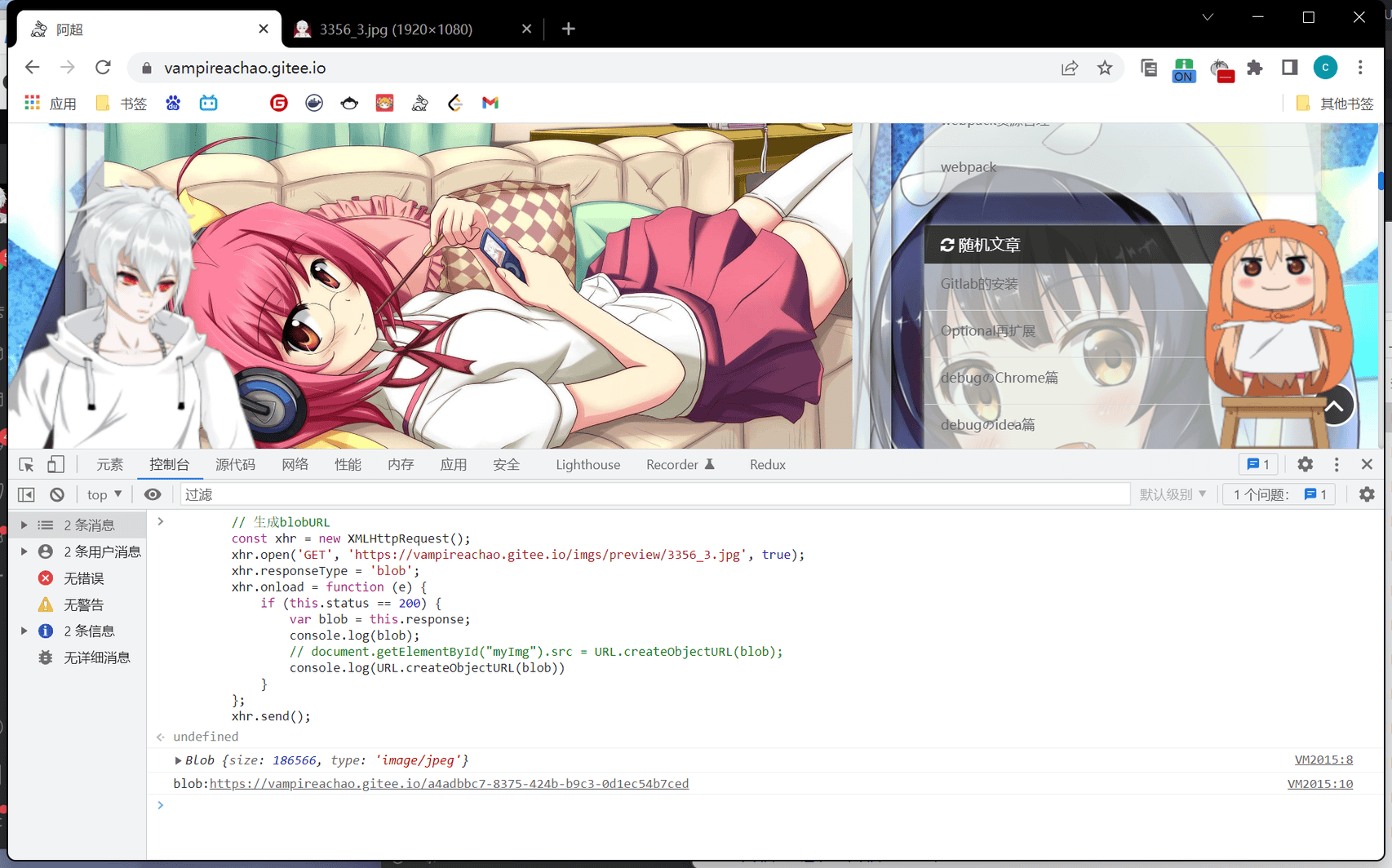
尝试新标签打开,404
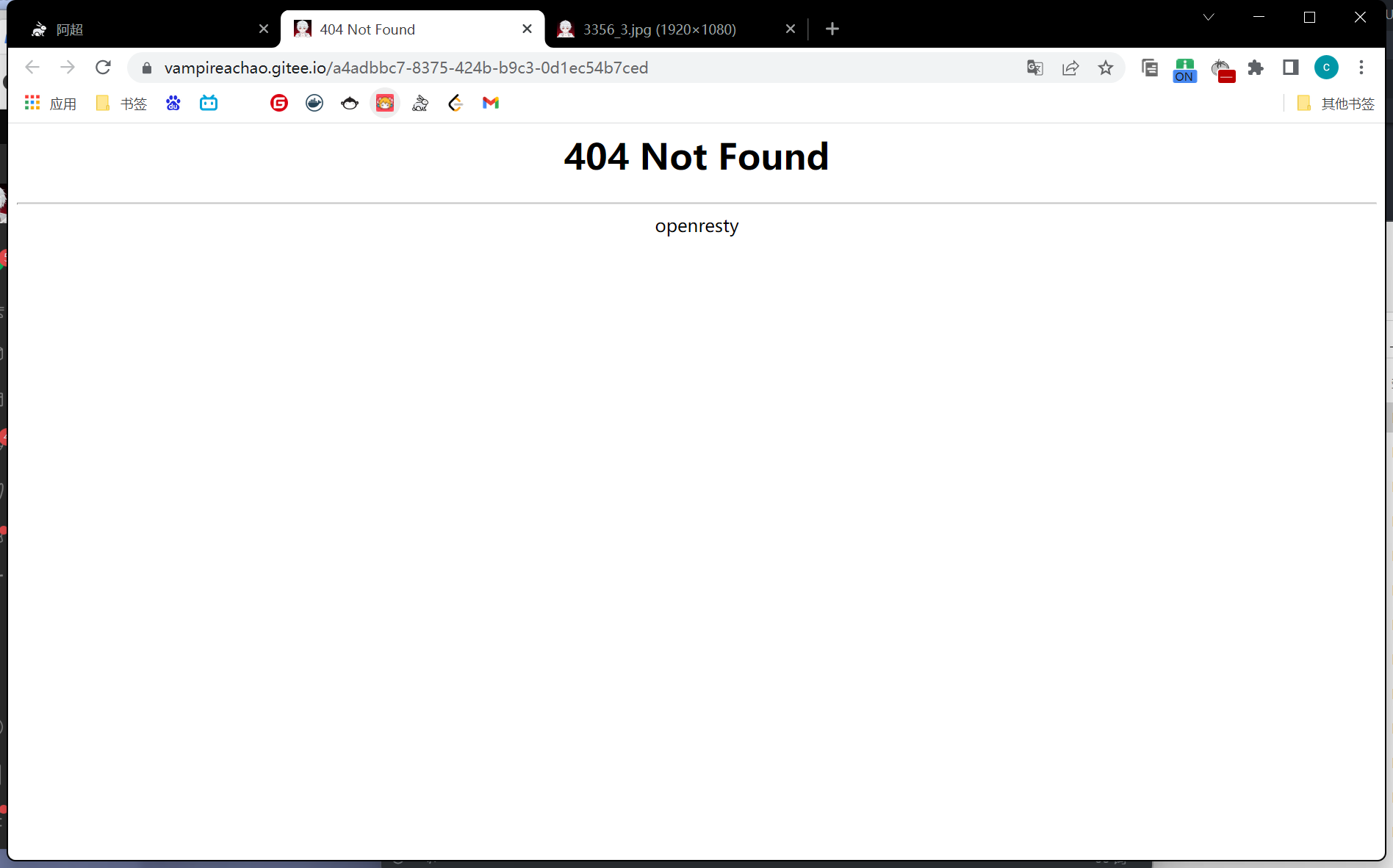
但是我们直接替换img src,成功渲染
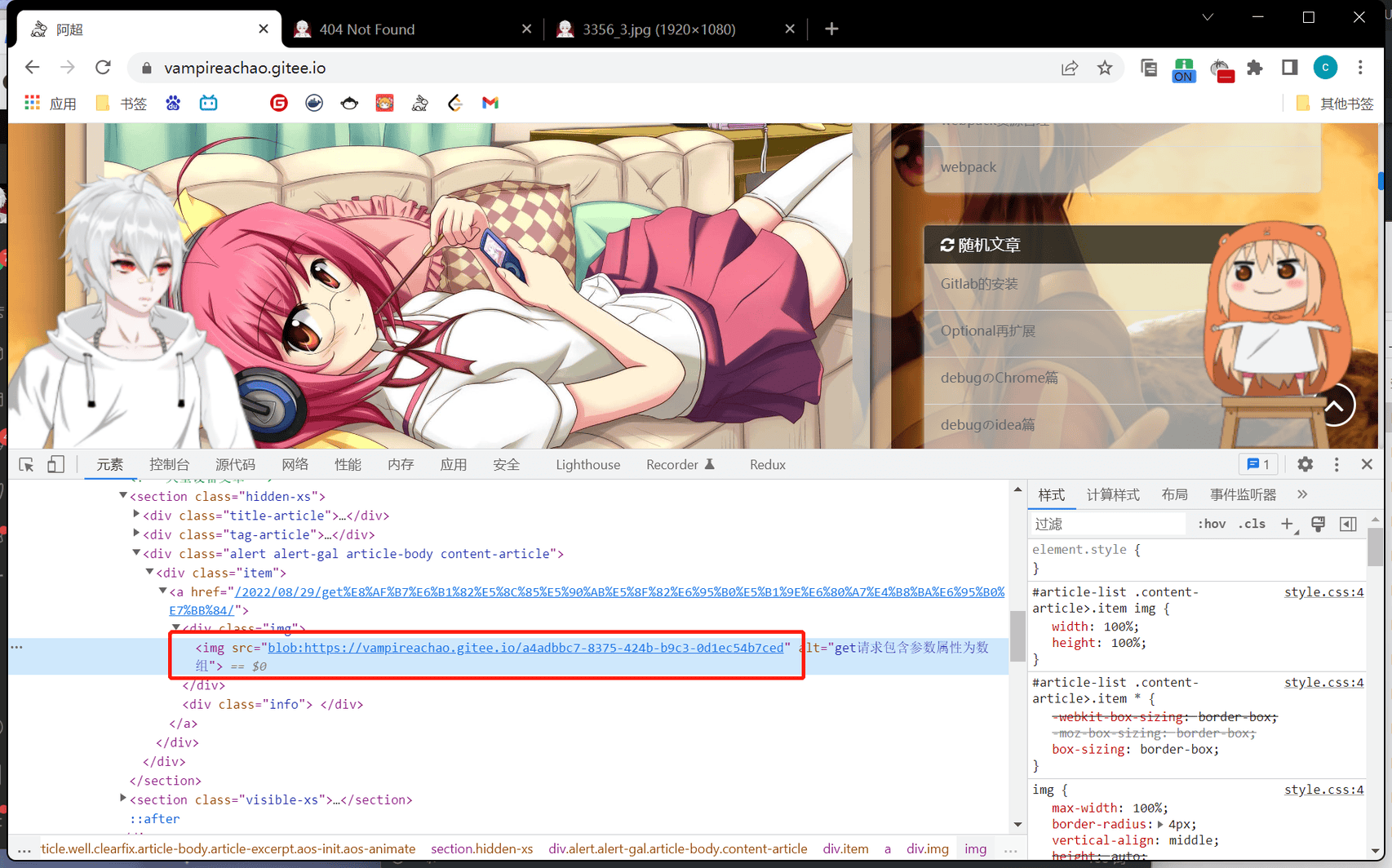
如果一开始将图片格式转为webp,能阻挡大部分爬虫了
那么如果遇到blob:开头的blobUrl,怎么下载呢?.
用下面的js
1
2
3
4
5
6
7
8
9
10
11
12
13
|
const filename = '3356_3.jpg'
const blobUrlString = 'blob:https://VampireAchao.github.io/a4adbbc7-8375-424b-b9c3-0d1ec54b7ced'
fetch(blobUrlString)
.then((response) => response.blob())
.then((blob) => {
let aLink = document.createElement('a')
let evt = document.createEvent('HTMLEvents')
evt.initEvent('click', true, true)
aLink.download = filename
aLink.href = URL.createObjectURL(blob)
aLink.click()
})
|
成功下载