我要让全世界都记住我的温柔。——曼德拉
上次咱们测试过了单表多次查询和连表一次查询的性能比较
这次咱们又抽了点时间进行了一次 循坏调用dao查询性能测试
同样是那一百万条数据,最后测试结果出乎意料
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| @Test
public void cycleTest() {
long startTime = System.nanoTime();
List<Film> films = filmMapper.selectList(Wrappers.lambdaQuery());
List<Map<String, Object>> collect = films.stream().map(film -> {
Language language = languageMapper.selectById(film.getLanguageId());
Language language1 = languageMapper.selectById(film.getLanguageId());
Map<String, Object> map = BeanUtils.beanToMap(film);
map.putAll(BeanUtils.beanToMap(language));
map.putAll(BeanUtils.beanToMap(language1));
return map;
}).collect(Collectors.toList());
long endTime = System.nanoTime();
System.out.println("耗时:" + ((endTime - startTime) / (1000.0 * 1000.0)) + " ms");
}
|
我们left join连表一次查询需要33秒左右
单表查询多次拿到同样的结果+使用并行流处理需要22秒左右
循环调用dao去selectById则花费了我们五分钟!!!
这只是从测试结果来看
实际我们可以追根溯源去源码中查看:
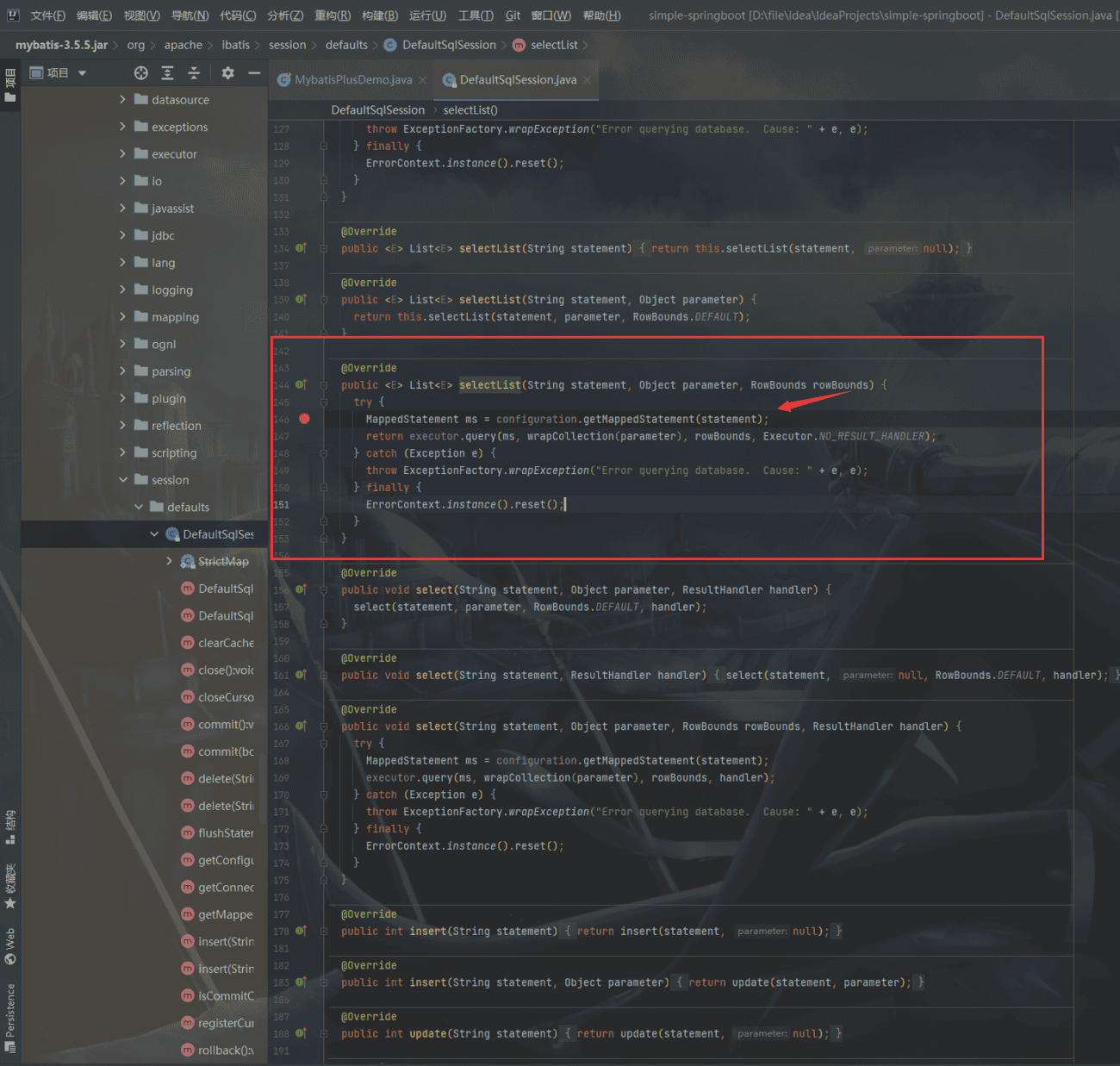
比如一个org.apache.ibatis.session.defaults.DefaultSqlSession#selectList(java.lang.String, java.lang.Object, org.apache.ibatis.session.RowBounds)
1
2
3
4
5
6
7
8
9
10
11
| @Override
public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) {
try {
MappedStatement ms = configuration.getMappedStatement(statement);
return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
|
可以看到我们是每次查询都去调用了getMappedStatement
通过日志也可以看出每次我们查询都会去创建SqlSession
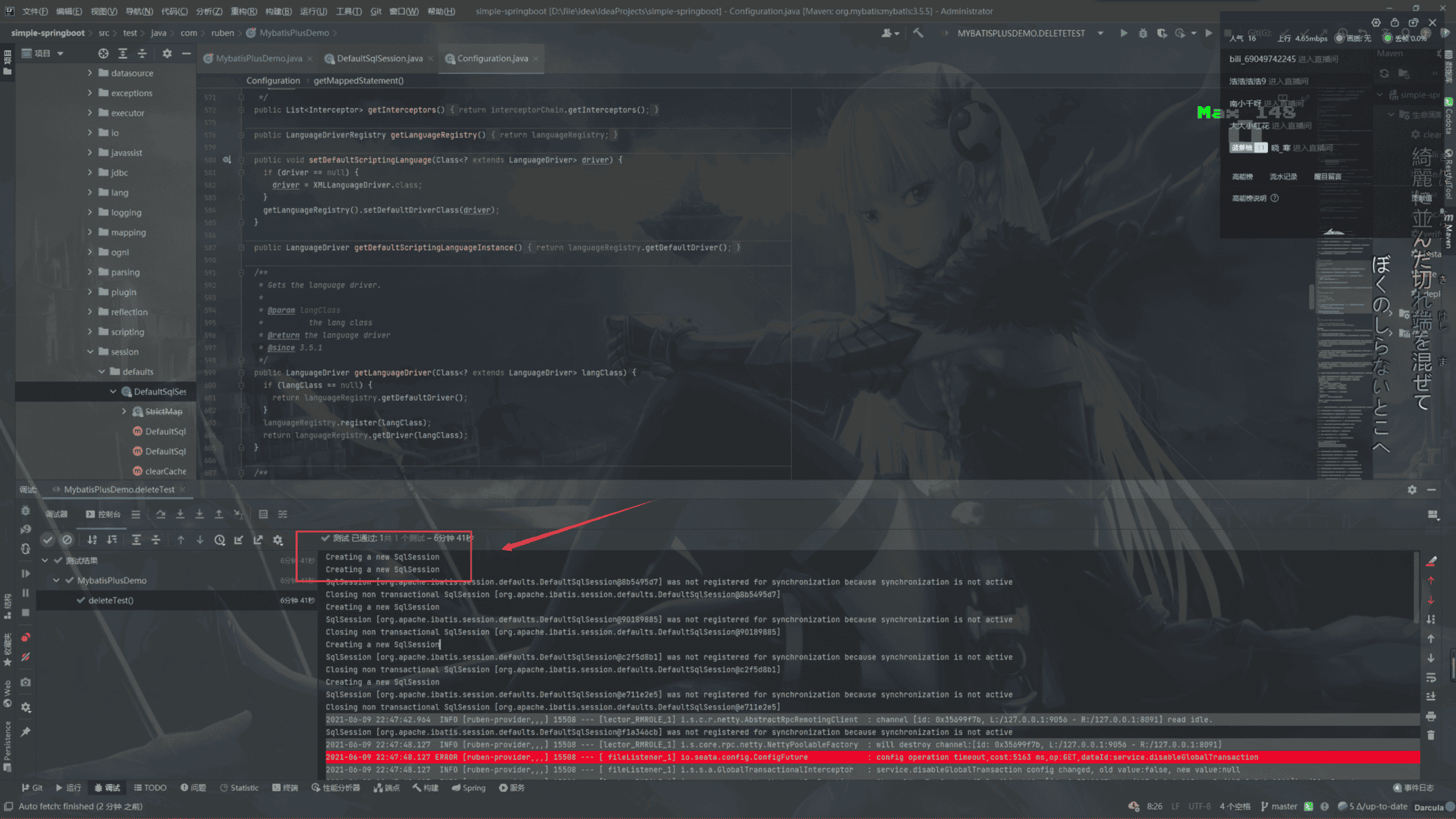
所以它的性能为什么这么慢。。。
