快乐,使生命得以延续。快乐,是精神和肉体的朝气,是希望和信念,是对自己的现在和来来的信心,是一切都该如此进行的信心。——果戈理
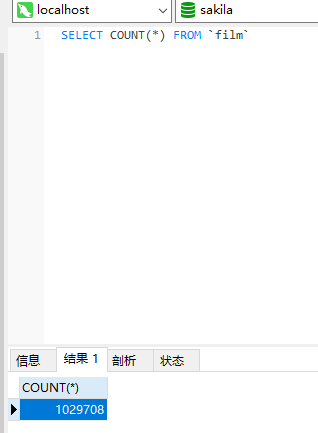
今天做了个小测试啊
我自己造了一百万多条(1029708条)数据
这里测试呢我们首先是编写了一个LEFT JOIN
连表SQL如下
1 2 3 SELECT * FROM `film` LEFT JOIN `language ` ON `film`.language_id = `language `.language_id
我们查询一百万多条后耗时为33457.8317 ms,大约30来秒,这是没有加索引的情况下
我们使用单表查询,然后再拼装
1 2 3 4 5 6 7 8 9 10 11 long startTime = System.nanoTime();List<Film> films = filmMapper.selectList(Wrappers.lambdaQuery()); List<Integer> languageIds = films.parallelStream().map(Film::getLanguageId).distinct().collect(Collectors.toList()); final Map<Integer, Language> languageMap = languageMapper.selectList(Wrappers.lambdaQuery(Language.builder().build()).in(Language::getLanguageId, languageIds)).parallelStream().collect(Collectors.toMap(Language::getLanguageId, Function.identity(), (v1, v2) -> v2));List<Map<String, Object>> collect = films.stream().map(film -> { Map<String, Object> map = BeanUtils.beanToMap(film); Optional.ofNullable(film).map(Film::getLanguageId).map(languageMap::get).map(BeanUtils::beanToMap).ifPresent(map::putAll); return map; }).collect(Collectors.toList()); long endTime = System.nanoTime();System.out.println("耗时:" + ((endTime - startTime) / (1000.0 * 1000.0 )) + " ms" );
最后耗时为22289.5385 ms,大约20来秒,可以看到明显比上面的连表查询要快
那么如果再连一次呢,模拟两个LEFT JOIN的场景
1 2 3 4 SELECT * FROM `film` LEFT JOIN `language ` ON `film`.language_id = `language `.language_id LEFT JOIN `language ` AS language1 ON `film`.language_id = language1.language_id
这里耗时37053.9295 ms,因为我们language表数据量较小,所以再连一次差别也并不是特别大
但可以明显看出,多了4秒左右
我们写成单表的话
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 long startTime = System.nanoTime(); List<Film> films = filmMapper.selectList(Wrappers.lambdaQuery()); List<Integer> languageIds = films.parallelStream().map(Film::getLanguageId).distinct().collect(Collectors.toList()); CompletableFuture<Map<Integer, Language>> languageMapFuture = CompletableFuture.supplyAsync(() -> languageMapper.selectList(Wrappers.lambdaQuery(Language.builder().build()).in(Language::getLanguageId, languageIds)).parallelStream().collect(Collectors.toMap(Language::getLanguageId, Function.identity(), (v1, v2) -> v2))); CompletableFuture<Map<Integer, Language>> languageMapFuture1 = CompletableFuture.supplyAsync(() -> languageMapper.selectList(Wrappers.lambdaQuery(Language.builder().build()).in(Language::getLanguageId, languageIds)).parallelStream().collect(Collectors.toMap(Language::getLanguageId, Function.identity(), (v1, v2) -> v2))); CompletableFuture.allOf(languageMapFuture, languageMapFuture1).get(); Map<Integer, Language> languageMap = languageMapFuture.get(); Map<Integer, Language> languageMap1 = languageMapFuture1.get(); List<Map<String, Object>> collect = films.stream().map(film -> { Map<String, Object> map = BeanUtils.beanToMap(film); Optional.ofNullable(film).map(Film::getLanguageId).map(languageMap::get).map(BeanUtils::beanToMap).ifPresent(map::putAll); Optional.ofNullable(film).map(Film::getLanguageId).map(languageMap1::get).map(BeanUtils::beanToMap).ifPresent(map::putAll); return map; }).collect(Collectors.toList()); long endTime = System.nanoTime(); System.out.println("耗时:" + ((endTime - startTime) / (1000.0 * 1000.0 )) + " ms" );
执行后耗时23362.9739 ms!!发现仅仅多了一秒左右啊
上面的连表SQL,就算在language表的language_id上加了索引,也是耗时35314.184 ms
也远远没有我们的单表快
所以结论:
同样的数据,单表多次查询在正确使用下,比连表确实快不少
但连表只需要一条SQL而单表需要写一大堆代码